
You are currently browsing the category archive for the ‘educational’ category.
Next up in the mini-course on data streams (first two lectures here and here) were lower bounds and communication complexity. The slides are here:

The outline was:
- Basic Framework: If you have a small-space algorithm for stream problem
, you can turn this into a low-communication protocol for a related communication problem
. Hence, a lower bound on the communication required to solve
- Information Statistics: So how do we prove communication lower bounds? One powerful method is to analyze the information that is revealed about a player’s input by the messages they send. We first demonstrated this approach via the simple problem of indexing (a neat pedagogic idea courtesy of Amit Chakrabarti) before outlining how the approach would extend to the disjointness problem.
- Hamming Distance: Lastly, we presented a lower bound on the Hamming approximation problem using the ingenious but simple proof [Jayram et al.]
Tout le monde! Here’s the group photo from this year’s L’Ecole de Printemps d’Informatique Théorique.

Everyone loves the union bound. It is the most dependable of all probability bounds. No matter what mess of dependencies threaten your analysis, the union bound will ride in and save the day. Except when it doesn’t.
I’ve been giving a talk about some recent results (here are some slides) and have received a particular question from a couple of different audiences. The exact details aren’t important but the basic gist was why I didn’t simplify some of the analysis by just applying the union bound. The short answer was it didn’t apply. But how could that be? My longer answer was longer and probably less helpful. So let me distill things down to the following paradox (which isn’t really a paradox of course).
The Geography Test. Suppose you have a geography test tomorrow. In the test you’ll be asked two questions out of five possible questions (and you already know the list of possible questions). If you get both right, you’ll pass the course. However, rather than revise everything you adopt a random strategy that ensures that for any question, you’ll have a correct answer with probability at least 4/5. Hence, by the union bound, you’ll get both questions right with probability at least 3/5.
Right? Sure, it’s a straight-forward application of the union bound: the probability of being wrong on one or both questions is at most the probability of being wrong on the first (at most 1/5) plus the probability of being wrong on the second (at most 1/5). And the union bound never let’s you down.
The Bad News. You’re going to fail both your geography and probability classes. Consider the following scenario. The five possible exam questions are: 1) name a city in the US, 2) name a city in France, 3) name a city in Germany, 4) name a city in the UK, and 5) name a city in Italy. Your cunning strategy is to memorize one of the rows in the following table.
| US | France | Germany | UK | Italy |
|---|---|---|---|---|
| New York | Paris | Berlin | Glasgow | Reykjavik |
| Philadelphia | Paris | Berlin | Reykjavik | Rome |
| Los Angeles | Paris | Reykjavik | Glasgow | Rome |
| Boston | Reykjavik | Berlin | Glasgow | Rome |
| Reykjavik | Paris | Berlin | Glasgow | Rome |
You choose the row to remember uniformly at random thus guaranteeing that you can answer any question correctly with probability 4/5. Of course the professor doesn’t know which row you’ll pick but he does know your strategy. (This is equivalent to the usual assumption we make about adversaries knowing your algorithm but not your random bits.)
Unfortunately, you stay up so late studying your row that you sleep in and miss the exam. You go to the professor’s office to plead for a make-up exam. He is initially reluctant but then a devious smile crosses his face. Sure, he’ll still give you the exam. You’re relieved that you’ll still pass the course with probability at least 3/5. The professor doesn’t look so sure.
The first question he asks is to name a city in the US. “Philadelphia” you answer with confidence. As the professor nods you see that devious smile again. The second question… name a city in the UK.
And then you realize that the probability of success was never as large as 3/5 since the professor could always guarantee that you fail by first asking for a US city and then choosing his second question accordingly.
Morals of the story: Don’t miss exams, study hard, and don’t blindly trust the union bound.
Here’s another bite-sized stream algorithm for your delectation. This time we want to simulate a random walk from a given node 


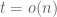
This is trivial if you take 
Well, here’s an algorithm from [Das Sarma, Gollapudi, Panigrahy] that simulates a random walk of length 
- We first compute short random walks from each node. Using the trivial algorithm, do a length
walk from each node
and let
be the end point.
- We can’t reuse short random walks (otherwise the steps in the random walk won’t be independent) so let
be the set of nodes from which we’re already taken a short random walk. To start, let
and
where
is the length of this random walk.
- While
- If
then set
- Otherwise, sample
-th visit to node
, we take the
- Perform the remaining

![v\leftarrow T[v], \ell \leftarrow \sqrt{t}+\ell, S\leftarrow S\cup \{v\}](https://s0.wp.com/latex.php?latex=v%5Cleftarrow+T%5Bv%5D%2C+%5Cell+%5Cleftarrow+%5Csqrt%7Bt%7D%2B%5Cell%2C+S%5Cleftarrow+S%5Ccup+%5C%7Bv%5C%7D&bg=ffffff&fg=545454&s=0&c=20201002)
So why does it work? First note that the maximum size of 





Das Sarma et al. also present a trade-off result that reduces the space to 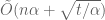
![\alpha\in (0,1]](https://s0.wp.com/latex.php?latex=%5Calpha%5Cin+%280%2C1%5D&bg=ffffff&fg=545454&s=0&c=20201002)

Following on from the last post on maximum weighted matchings in the stream model, I wanted to briefly mention a result that appeared in STACS last week. The set-up is the same as before: there’s a stream of undirected weighted edges 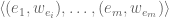
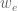

Which brings us to [Epstein, Levin, Mestre, Segev]. They showed a lower bound of 4.967 for any deterministic preemptive online algorithm. Furthermore, they show that there exists a deterministic stream algorithm that breaks through this bound and achieves a 4.911 approximation. As a commenter pointed out, the algorithm is nice and simple. Furthermore, it makes a good teaching example of how algorithms don’t necessary appear from thin air, but rather can be developed in a series of less mysterious steps. Here’s what they do in the paper:
- Design a simple deterministic 8-approximation: Geometrically group edge weights by rounding edge weight to the nearest power of 2 and ignore the “very light” edges. Greedily find a maximal matching among each group of edges. At the end of the stream, find a maximum matching among the stored edges.
- Randomize the algorithm to get a 4.911-approximation: Instead of grouping to the nearest power of 2, do randomized geometric grouping with the appropriate parameters.
- Derandomize!

Thought… It might be interesting to investigate which other problems exhibit a separation between the preemptive online model and the stream model. You may need to be flexible with your definition of “preemptive online.”
Readers with a particularly long memory may recall that we’re in the midst of a series of “bite-sized results” in data stream algorithms. Back in October, we discussed graph spanners and now it’s time for some graph matchings.
So consider a stream of undirected weighted edges
Here’s a really simple algorithm that maintains a matching as the edges are processed:
- The initial matching is the empty matching
- When processing edge
of the conflicting edges, i.e., the edges in the currently stored matching that share an endpoint with
then
It makes a nice exercise to prove that the above algorithm achieves a 
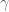
Subsequently, a 5.585 approximation algorithm was presented in [Zelke]. The main idea was to remember some of the edges that were ejected from the matching in the second step of the above algorithm. These edges are potentially added back into the matching at some later point. While a natural idea, it requires substantially more analysis to show the improved approximation ratio.
The last four BSS posts considered streams of numerical values. While there are still many more bite-sized results to cover for such streams, I thought we’d mix things up a bit and switch to graph streams for the next four posts. We’ll consider a stream of unweighted, undirected edges 
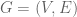
The results we’ll discuss revolve around constructing a 



where 
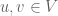


So how can we construct a 
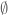

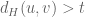
It’s easy to show that 
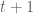

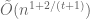
Unfortunately, the time to process each edge in the above algorithm is rather large and this spurred some nice follow-up work including [Feigenbaum et al.], [Baswana], and [Elkin]. It’s now known how to construct a
It’s not hard to extend these algorithms to weighted graphs (consider geometrically grouping the edge weights and constructing a spanner for each distinct edge weight) but there’s bad news for directed graphs: even determining if there exists a directed path between two nodes requires 
BONUS! Some British English… Back in the UK, we call this

a spanner. Apparently that’s not the usual term in US English and I found this out after giving a talk at SODA back in 2005. The talk went reasonably well but, during the coffee break, numerous people asked why I’d kept on displaying pictures of wrenches throughout my talk. Whoops.
In technical writing, I normally endeavor [sic] to use US English (although I did once engage in some “colouring of paths” in a paper with a Canadian co-author). But I still think “math and stat” sounds funny :)
My Biased Coin recently discussed a new paper extending some work I’d done a few years back. I’ll briefly mention this work at the end of the post but first here’s another bite-sized result from [Alon, Matias, Szegedy] that is closely related.
Consider a numerical stream that defines a frequency vector 
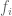

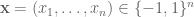
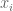
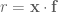

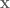
By the weaker assumption of 2-wise independence, we observe that ![E[x_i x_j]=0](https://s0.wp.com/latex.php?latex=E%5Bx_i+x_j%5D%3D0&bg=ffffff&fg=545454&s=0&c=20201002)
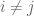
![E[r^2]=\sum_{i,j\in [n]} f_i f_j E[x_i x_j]=F_2](https://s0.wp.com/latex.php?latex=E%5Br%5E2%5D%3D%5Csum_%7Bi%2Cj%5Cin+%5Bn%5D%7D+f_i+f_j+E%5Bx_i+x_j%5D%3DF_2&bg=ffffff&fg=545454&s=0&c=20201002)
By the assumption of 4-wise independence, we also observe that ![E[x_i x_j x_k x_l]=0](https://s0.wp.com/latex.php?latex=E%5Bx_i+x_j+x_k+x_l%5D%3D0&bg=ffffff&fg=545454&s=0&c=20201002)
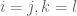

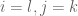
![\mbox{Var}[r^2]= \sum_{i,j,k,l\in [n]} f_i f_j f_k f_l E[x_i x_j x_k x_l]-F_2^2=4\sum_{i<j} f_i^2f_j^2\leq 2 F_2^2](https://s0.wp.com/latex.php?latex=%5Cmbox%7BVar%7D%5Br%5E2%5D%3D+%5Csum_%7Bi%2Cj%2Ck%2Cl%5Cin+%5Bn%5D%7D+f_i+f_j+f_k+f_l+E%5Bx_i+x_j+x_k+x_l%5D-F_2%5E2%3D4%5Csum_%7Bi%3Cj%7D+f_i%5E2f_j%5E2%5Cleq+2+F_2%5E2&bg=ffffff&fg=545454&s=0&c=20201002)
Hence, if we repeat the process with 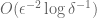
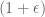
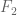
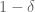


BONUS! The recent work… Having at least 4-wise independence seemed pretty important to getting a good bound on the variance of 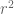
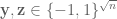

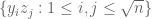
![\mbox{Var}[r^2]=O(F_2^2)](https://s0.wp.com/latex.php?latex=%5Cmbox%7BVar%7D%5Br%5E2%5D%3DO%28F_2%5E2%29&bg=ffffff&fg=545454&s=0&c=20201002)
In follow up work by [Braverman, Ostrovsky] and [Chung, Liu, Mitzenmacher], it was shown that you can push this idea further and define 

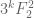
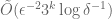
At this point, you’d be excused for asking why we all cared about such a construction. The reason is that it’s an important technical step in solving the following problem: given a stream of tuples from ![[n]^k](https://s0.wp.com/latex.php?latex=%5Bn%5D%5Ek&bg=ffffff&fg=545454&s=0&c=20201002)
If you want to measure independence in terms of the variational distance, check out [Braverman, Ostrovsky]. In the case 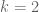
We’re presented with a numerical stream ![A=\langle a_1, \ldots, a_m\rangle\in [n]^m](https://s0.wp.com/latex.php?latex=A%3D%5Clangle+a_1%2C+%5Cldots%2C+a_m%5Crangle%5Cin+%5Bn%5D%5Em&bg=ffffff&fg=545454&s=0&c=20201002)


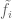
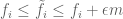
where 
Let 
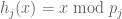
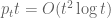
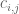


![j\in [t]](https://s0.wp.com/latex.php?latex=j%5Cin+%5Bt%5D&bg=ffffff&fg=545454&s=0&c=20201002)
Say we’re interested in the frequency of 
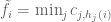
Note that for any 
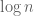




and therefore 
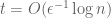
But wait, there’s more! There are actually other deterministic algorithms for this problem that use only 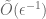
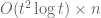

![A=\langle a_1, \ldots, a_m\rangle\in (\{-,+\}\times [n])^m](https://s0.wp.com/latex.php?latex=A%3D%5Clangle+a_1%2C+%5Cldots%2C+a_m%5Crangle%5Cin+%28%5C%7B-%2C%2B%5C%7D%5Ctimes+%5Bn%5D%29%5Em&bg=ffffff&fg=545454&s=0&c=20201002)
and define
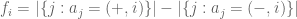
Assuming that all 


Gödel’s Lost Letter recently mentioned one of my favourite papers from the prehistory of data streams: Selection and Sorting with Limited Storage [Munro, Paterson]. It’s a great paper that prefigured many interesting research directions including multi-pass algorithms and processing streams in random order. Here’s one of the nice “bite-sized” results.
We consider a stream 


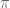
![[m]](https://s0.wp.com/latex.php?latex=%5Bm%5D&bg=ffffff&fg=545454&s=0&c=20201002)
Here’s a simple algorithm that maintains a set 

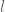

- If
Increment
- If
Increment
- If
and
: Add
- If
: Add
At the end of the stream, if 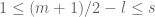
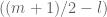
Why does the algorithm make sense? It’s easy to show that at any point, the set of elements that has arrived thus far consists of 
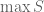


- Probability a non-zero
- If
at the final step, then
Hence, we have a simple “random-walk-like” set-up and there’s a
Of course you could ask about finding approximate medians of randomly ordered streams in one or more passes. If you do, check out [Guha, McGregor], [Chakrabarti, Jayram, Patrascu], and [Chakrabarti, Cormode, McGregor].
We’re presented with a numerical stream ![\sum_{i\in [n]} g(f_i)](https://s0.wp.com/latex.php?latex=%5Csum_%7Bi%5Cin+%5Bn%5D%7D+g%28f_i%29&bg=ffffff&fg=545454&s=0&c=20201002)
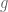

- Pick
uniformly at random from
- Compute
- Let

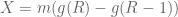
Note that 
![E[X]=\sum_{i\in [n]} g(f_i)](https://s0.wp.com/latex.php?latex=E%5BX%5D%3D%5Csum_%7Bi%5Cin+%5Bn%5D%7D+g%28f_i%29&bg=ffffff&fg=545454&s=0&c=20201002)
![E[X]= \sum_{i} E[X|a_J=i] \Pr[a_J=i]=\sum_{i} E[g(R)-g(R-1)|a_J=i] f_i](https://s0.wp.com/latex.php?latex=E%5BX%5D%3D+%5Csum_%7Bi%7D+E%5BX%7Ca_J%3Di%5D+%5CPr%5Ba_J%3Di%5D%3D%5Csum_%7Bi%7D+E%5Bg%28R%29-g%28R-1%29%7Ca_J%3Di%5D+f_i&bg=ffffff&fg=545454&s=0&c=20201002)
and
![E[g(R)-g(R-1)|a_J=i] = \frac{g(1)-g(0)}{f_i}+\ldots + \frac{g(f_i)-g(f_i-1)}{f_i}=\frac{g(f_i)}{f_i}\ .](https://s0.wp.com/latex.php?latex=E%5Bg%28R%29-g%28R-1%29%7Ca_J%3Di%5D+%3D+%5Cfrac%7Bg%281%29-g%280%29%7D%7Bf_i%7D%2B%5Cldots+%2B+%5Cfrac%7Bg%28f_i%29-g%28f_i-1%29%7D%7Bf_i%7D%3D%5Cfrac%7Bg%28f_i%29%7D%7Bf_i%7D%5C+.&bg=ffffff&fg=545454&s=0&c=20201002)
Hence, computing multiple basic estimators in parallel and averaging appropriately will give a good estimate of
Using this approach, it was shown that the ![F_k=\sum_{i\in [n]} f_i^k](https://s0.wp.com/latex.php?latex=F_k%3D%5Csum_%7Bi%5Cin+%5Bn%5D%7D+f_i%5Ek&bg=ffffff&fg=545454&s=0&c=20201002)



Recent Comments