(Jelani Nelson reports from Sublinear Algorithms 2011.)
It’s the first day of talks at the 2011 Bertinoro workshop on sublinear algorithms (titles and abstracts), about one hour’s drive southeast of Bologna, Italy. The day started off with some introductions. Everyone stated their name, affiliation, and often some of their research interests, while Amit Chakrabarti and Graham Cormode spiced up the routine by introducing each other.
Dana Ron gave the first talk: a survey talk on sublinear time algorithms for approximating graph parameters. She talked about estimating average degree, min-weight MST, vertex cover/max matching, and distance to various graph properties (like  -connectivity), and she considered various query models. The [Feige] algorithm for average degree estimation algorithm vaguely reminded me of the [Indyk, Woodruff] algorithm for estimating frequency moments: break up vertices (or coordinates) into groups based on how much they contribute to the statistic at hand, then estimate sizes of groups that “matter” (i.e., are big enough). They both even use sampling and argue that groups that matter survive the sampling and can be noticed. Feige gets a
-connectivity), and she considered various query models. The [Feige] algorithm for average degree estimation algorithm vaguely reminded me of the [Indyk, Woodruff] algorithm for estimating frequency moments: break up vertices (or coordinates) into groups based on how much they contribute to the statistic at hand, then estimate sizes of groups that “matter” (i.e., are big enough). They both even use sampling and argue that groups that matter survive the sampling and can be noticed. Feige gets a 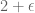 -approximation using degree queries. [Goldreich, Ron] gets a
-approximation using degree queries. [Goldreich, Ron] gets a 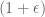 -approximation using neighbor queries. Oddly enough, I’ve seen this Feige paper before, but for a totally different reason. There’s a disturbingly simple to state, but still open problem left in his paper which I once failed to solve with a friend one evening:
-approximation using neighbor queries. Oddly enough, I’ve seen this Feige paper before, but for a totally different reason. There’s a disturbingly simple to state, but still open problem left in his paper which I once failed to solve with a friend one evening:
OPEN: If 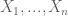 are independent nonnegative random variables each with expectation
are independent nonnegative random variables each with expectation  , then what’s the largest constant
, then what’s the largest constant  so that
so that ![Pr[\sum_i X_i < n+1] \ge c](https://s0.wp.com/latex.php?latex=Pr%5B%5Csum_i+X_i+%3C+n%2B1%5D+%5Cge+c&bg=ffffff&fg=545454&s=0&c=20201002) ? Feige proves
? Feige proves 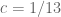 works, but he conjectures the right answer is
works, but he conjectures the right answer is  .
.
The next talk was by Krzysztof Onak, who focused more on vertex cover (VC) and max-matching. He focused on getting a  -approximation (i.e., output an answer between
-approximation (i.e., output an answer between 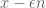 and
and  , where
, where  is the true answer). We assume queries ask for the
is the true answer). We assume queries ask for the  th neighbor of a vertex. [Parnas, Ron] got
th neighbor of a vertex. [Parnas, Ron] got 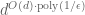 queries. [Nguyen, Onak] improved this to
queries. [Nguyen, Onak] improved this to  , followed by
, followed by  [Yoshida, Yamamoto, Ito]. [Onak, Ron, Rosen, Rubinfeld] most recently got
[Yoshida, Yamamoto, Ito]. [Onak, Ron, Rosen, Rubinfeld] most recently got  , which is the optimal dependence on
, which is the optimal dependence on  . Krzysztof tells me the techniques can also give
. Krzysztof tells me the techniques can also give 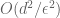 . The idea for say, VC, is to first reduce to an oracle which can tell you whether any vertex
. The idea for say, VC, is to first reduce to an oracle which can tell you whether any vertex  is inside a particular VC which is at most two times worse than the optimal one. With such an oracle, you can just sample and use the Hoeffding bound. The trick is then to implement the oracle, and various authors starting from Parnas-Ron designed have been designing and implementing slicker and slicker oracles.
is inside a particular VC which is at most two times worse than the optimal one. With such an oracle, you can just sample and use the Hoeffding bound. The trick is then to implement the oracle, and various authors starting from Parnas-Ron designed have been designing and implementing slicker and slicker oracles.
OPEN: Is there a good 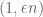 -approximation for maximum matching? Right now the best bound is
-approximation for maximum matching? Right now the best bound is  queries, but what about
queries, but what about 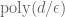 ? How about
? How about  for planar graphs?
for planar graphs?
Justin Romberg followed up with a survey on compressed sensing. The idea is to take few linear measurements, e.g., 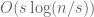 , of an
, of an  -dimensional vector such that the best
-dimensional vector such that the best  -term approximation of can be nearly recovered from the measurements. One of the defining papers of the field, by Candes, Romberg, and Tao, shows that such a thing is possible via “
-term approximation of can be nearly recovered from the measurements. One of the defining papers of the field, by Candes, Romberg, and Tao, shows that such a thing is possible via “ minimization” as long as the measurement matrix satisfies a certain restricted isometry property (“RIP”), i.e. it nearly preserves Euclidean norms of all sparse vectors. How does one get such matrices? [Baraniuk, Davenport, DeVore, Wakin] show that sampling from a “Johnson-Lindenstrauss” distribution gives RIP with high probability. And in fact, there’s a really neat paper by [Krahmer, Ward], following work by [Ailon, Liberty], that RIP matrices also give JL distributions so that there’s a near-equivalence; I’d even go as far as to say that [Krahmer, Ward] is my favorite paper of 2010. So, random Gaussian entries work, or even the Fast JL transform of [Ailon, Chazelle]. It also works to randomly subsample rows of the Fourier matrix, or take a random partial Toeplitz matrix, but then you need
minimization” as long as the measurement matrix satisfies a certain restricted isometry property (“RIP”), i.e. it nearly preserves Euclidean norms of all sparse vectors. How does one get such matrices? [Baraniuk, Davenport, DeVore, Wakin] show that sampling from a “Johnson-Lindenstrauss” distribution gives RIP with high probability. And in fact, there’s a really neat paper by [Krahmer, Ward], following work by [Ailon, Liberty], that RIP matrices also give JL distributions so that there’s a near-equivalence; I’d even go as far as to say that [Krahmer, Ward] is my favorite paper of 2010. So, random Gaussian entries work, or even the Fast JL transform of [Ailon, Chazelle]. It also works to randomly subsample rows of the Fourier matrix, or take a random partial Toeplitz matrix, but then you need  measurements. Actually, the Toeplitz construction is really neat in that it’s “universal”: you get small error as long as the is (near-)sparse in some basis, which you don’t need to know in advance.
measurements. Actually, the Toeplitz construction is really neat in that it’s “universal”: you get small error as long as the is (near-)sparse in some basis, which you don’t need to know in advance.
OPEN: How do you check that a matrix satisfies RIP? Can we do away with RIP and get a computable guarantee for sparse recovery?
Next was Piotr Indyk, who gave a talk on adaptive compressed sensing (joint work with Eric Price and David Woodruff). The question is: if we can look at the output of previous measurements before deciding what to measure next, can we do better? It turns out that you can! Whereas [Do Ba, Indyk, Price, Woodruff] and [Foucart, Pajor, Rauhut, Ullrich] showed that  is a lower bound in the non-adaptive setting, in the adaptive case it turns out
is a lower bound in the non-adaptive setting, in the adaptive case it turns out  measurements is possible. In fact, only
measurements is possible. In fact, only  rounds of adaptiveness are required, where the # is yet-to-be-determined (
rounds of adaptiveness are required, where the # is yet-to-be-determined ( is at least doable for now). The algorithm was nifty in that, as in other linear sketches, you do some hashing and random signs, but at some point you actually take what’s in some counters and round to the nearest integer. Kind of funky.
is at least doable for now). The algorithm was nifty in that, as in other linear sketches, you do some hashing and random signs, but at some point you actually take what’s in some counters and round to the nearest integer. Kind of funky.
OPEN: Lower bounds? What if there’s noise after the measurements? And, deterministic schemes?
Off to lunch…


Leave a comment
Comments feed for this article