(Krzysztof Onak continues with Tuesday’s report for Sublinear Algorithms 2011.)
The second part of the day started with a session devoted to the Johnson-Lindenstrauss lemma. Nir Ailon presented different definitions of the problem. In the embedding version, one is given a set of  Euclidean vectors in
Euclidean vectors in  and wants to map them to
and wants to map them to  , where d is small and the lengths of vectors are preserved up to a factor of
, where d is small and the lengths of vectors are preserved up to a factor of  . It is known that a random projection on
. It is known that a random projection on 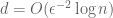 dimensions is likely to produce such vectors. The downsides of using a random projection are that both the running time and the required amount of randomness are
dimensions is likely to produce such vectors. The downsides of using a random projection are that both the running time and the required amount of randomness are 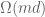 . Nir has addressed the challenge of reducing these requirements in his papers [Ailon, Chazelle] and [Ailon, Liberty]. His papers employ the Fourier transform and error correcting codes. Nir also discussed a more recently discovered connection between this problem and the restricted isometry property in compressed sensing. This connection resulted in new algorithms for efficiently computing the Johnson-Lindenstrauss transform.
. Nir has addressed the challenge of reducing these requirements in his papers [Ailon, Chazelle] and [Ailon, Liberty]. His papers employ the Fourier transform and error correcting codes. Nir also discussed a more recently discovered connection between this problem and the restricted isometry property in compressed sensing. This connection resulted in new algorithms for efficiently computing the Johnson-Lindenstrauss transform.

Jelani Nelson presented his recent paper with Daniel Kane. The goal is to give a distribution over sparse matrices that provides the properties required in the Johnson Linderstrauss lemma and can be computed efficiently for sparse vectors. Jelani’s work is a followup to the paper of [Dasgupta, Kumar, Sarlos]. Jelani showed two extremely simple methods for constructing such matrices. In the first, one selects a small number of entries in each column and sets them at random to  and
and  . In the other one, one partitions the rows into a number of buckets corresponding to the number of desired non-zero entries in each column. Then in each column, one chooses one non-zero entry in each bucket. The main advantage over the approach of Dasgupta et al. is that this way collisions between non-zero entries are avoided. One of the main open questions is to both derandomize the Johnson-Lindenstrauss transform and make it run fast for sparse vectors. Jelani also mentioned a recent follow-up by [Braverman, Ostrovsky, Rabani].
. In the other one, one partitions the rows into a number of buckets corresponding to the number of desired non-zero entries in each column. Then in each column, one chooses one non-zero entry in each bucket. The main advantage over the approach of Dasgupta et al. is that this way collisions between non-zero entries are avoided. One of the main open questions is to both derandomize the Johnson-Lindenstrauss transform and make it run fast for sparse vectors. Jelani also mentioned a recent follow-up by [Braverman, Ostrovsky, Rabani].

You can spend the following coffee break admiring one of the well preserved frescoes:

Sofya Raskhodnikova talked about the problems of testing and reconstructing Lipschitz functions [Jha, Raskhodnikova 2011]. A function 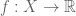 is
is  -Lipschitz if for every
-Lipschitz if for every 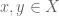 , it holds
, it holds  . In the testing problem, one wants to verify that a function is approximately Lipschitz (for some fixed ). In the reconstruction problem, one wants to design a “local filter” through which the question to a function are asked. If the distance of
. In the testing problem, one wants to verify that a function is approximately Lipschitz (for some fixed ). In the reconstruction problem, one wants to design a “local filter” through which the question to a function are asked. If the distance of  to the property of being Lipschitz is
to the property of being Lipschitz is 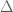 , then the filter provides access to a function
, then the filter provides access to a function 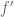 such that is Lipschitz, and the distance between and is not much larger than . Sofya mentioned applications of this research to program analysis and data privacy. In her presentation, she focused on the case when the domain
such that is Lipschitz, and the distance between and is not much larger than . Sofya mentioned applications of this research to program analysis and data privacy. In her presentation, she focused on the case when the domain  is a hypercube. She gave both positive and negative results, where she mentioned that the latter were greatly simplified by techniques from a recent paper of [Blais, Brody, Matulef].
is a hypercube. She gave both positive and negative results, where she mentioned that the latter were greatly simplified by techniques from a recent paper of [Blais, Brody, Matulef].

C. Seshadhri talked about his recent result on submod… Well, Sesh eventually decided to talk about approximating the length of the longest increasing subsequence [Saks, Seshadhri]. Sesh showed that an additive  -approximation to the length of the longest increasing subsequence can be computed in
-approximation to the length of the longest increasing subsequence can be computed in  time, where is the length of the sequence,
time, where is the length of the sequence,  is an arbitrary parameter, and is a constant. Before his work, the best known for which a sublinear algorithm was known was
is an arbitrary parameter, and is a constant. Before his work, the best known for which a sublinear algorithm was known was 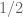 . This result also implies a better approximation algorithm for approximating the distance to monotonicity. Sesh showed a simplified version of his algorithm that runs in
. This result also implies a better approximation algorithm for approximating the distance to monotonicity. Sesh showed a simplified version of his algorithm that runs in  time. The algorithm mimics a dynamic program, recursively searches for good splitters, and applies some boosting to obtain a better approximation than
time. The algorithm mimics a dynamic program, recursively searches for good splitters, and applies some boosting to obtain a better approximation than  . Sesh also complained that working on the paper and making everything work was painful. He even explicitely asked: “Was it really worth it?” Sesh, I think it was. This is a really nice result!
. Sesh also complained that working on the paper and making everything work was painful. He even explicitely asked: “Was it really worth it?” Sesh, I think it was. This is a really nice result!

At night we experienced earthquakes, with the strongest of magnitude 3.1. It is pretty clear that they were caused by the impression left by today’s talks.
A screenshot from www.emsc-csem.org:



Leave a comment
Comments feed for this article