
(Piotr Indyk reports from Day 4 at Sublinear Algorithms. Includes contributions from Sariel Har Peled.)
The first session of the day was dedicated to distributed algorithms. It was headlined by Roger Wattenhofer, who gave a very nice overview of the area. Distributed algorithms have recently found applications in sub-linear world, e.g., see the talks on Monday. Distributed algorithms communicate along the edges of a graph, and the algorithm complexity is measured in rounds of communication.
The central character in Roger’s talk was the Maximal Independent Set (MIS) problem. Despite many years of research on this problem, some basic questions are still open (e.g., is there a deterministic algorithm with 
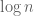



The next talk, by Pierre Fraigniaud, was on local distributed decisions (i.e., decision problems). An example of such problem is coloring validation: given a coloring, is it legal ? Other examples include: checking whether there is at most one marked node, consensus, etc. In general, one can define the notion of distributed language, which is a decidable collection of configurations. A configuration is accepted iff it is accepted by all nodes. In other words, the configuration is not accepted if someone says it is not accepted. Pierre presented several results on randomized algorithms for decision making, including a strong derandomization result (under certain conditions).
In the next session, Ning Xie talked about Local Computation Algorithms. Here the idea is that you are given the input, and problem at hand generates a large output. For example, the input is a graph and the task at hand is computing a maximal independent set (MIS). Let us assume that we want to output only one specific bit of the output. The question is whether we can do it in sublinear time, and in a way that is consistent, if we decide to read i bits of the output in some arbitrary fashion (i.e., think about the algorithm here is a query data-structure that outputs the desired bit). Since we need to be consistent across different queries, if we are going to use randomness, it needs to be compactly represented. To this end, one uses k-pairwise independent sequence of random bits, which can be specified compactly with a “few” random bits, and one can generate a long sequence implicitly that can “cheat” many algorithms. Secondary, to get a local computation, we need to be able to break up the input quickly into small fragments, such that the fragment that defines the desired output (i.e., it contains the vertex we need to output if it is in the MIS or not). The main idea is now to use Beck’s constructive version of the Lovasz Local Lemma. For example, you run a randomized MIS algorithm (parallel version) for a small number of iterations, and then you run a greedy algorithm on each remaining connected component. The randomized algorithm here chooses a vertex 




Yuichi Yoshida talked about constant-time approximation algorithms. He started from recalling the result of Raghavendra who showed that if the Unique Games Conjecture is true, then for every constraint satisfaction problem (CSP), the best approximation ratio is attained by a certain simple semidefinite programming and a rounding scheme for it. He then showed that similar results hold for constant- time approximation algorithms in the bounded-degree model. He obtained the results in three steps. First, he showed that for every CSP, one can construct an oracle that serves an access, in constant time, to a nearly optimal solution to a basic LP relaxation of the CSP. Using the oracle, he then showed a constant-time rounding scheme that achieves an approximation ratio coincident with the integrality gap of the basic LP. Finally, he gave a generic conversion from integrality gaps of basic LPs to hardness results.
The last talk before lunch was by Vladimir Braverman. He focused on the following class of streaming problems: given a function G, estimate a statistic that is equal to the sum, over all i, of terms 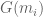




1 comment
Comments feed for this article
August 4, 2011 at 1:06 pm
Bertinoro Addendum « Machinations
[…] given at another workshop at Bertinoro this summer – a workshop on sublinear algorithms (blogged by Piotr Indyk here). Roger’s talk particularly focuses on lowerbounds and upperbounds for many “local […]