
This week, I’m at the Workshop on Algorithms for Data Streams in Dortmund, Germany. It’s a continuation in spirit of the great Kanpur workshops from 2006 and 2009.

The first day went very well despite the widespread jet lag (if only jet lag from those traveling from the east could cancel out with those traveling from the west.) Sudipto Guha kicked things off with a talk on combinatorial optimization problems in the (multiple-pass) data stream model. There was a nice parallel between Sudipto’s talk and a later talk by David Woodruff and both were representative of a growing number of papers that have used ideas developed in the context of data streams to design more efficient algorithms in the usual RAM model. In the case of Sudipto’s talk, this was a faster algorithm to approximate 
Other talks included Christiane Lammersen presenting a new result for facility location in data streams; Melanie Schmidt talking about constant-size coresets for 
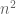

To be continued… Tomorrow, Suresh will post about day 2 across at the Geomblog.

3 comments
Comments feed for this article
July 29, 2012 at 8:17 pm
Data Streaming in Dortmund: Day 3 « the polylogblog
[…] Dortmund Workshop on Algorithms for Data Streams, here are the happens for Day 3. Previous posts: Day 1 and Day […]
September 17, 2012 at 9:44 am
Thought this was cool: Streaming Data Mining Tutorial slides (and more) « CWYAlpha
[…] Day 1 at Data Streaming in Dortmund: […]
February 6, 2013 at 6:01 pm
Best Computer Science Blogs of 2012
[…] to Begin: Read Data Streaming in Dortmund: Day 1, in which the author chronicles his trip to Germany for a workshop on algorithms for data […]