My Biased Coin recently discussed a new paper extending some work I’d done a few years back. I’ll briefly mention this work at the end of the post but first here’s another bite-sized result from [Alon, Matias, Szegedy] that is closely related.
Consider a numerical stream that defines a frequency vector  where
where 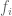 is the frequency of
is the frequency of  in the stream. Here’s a simple sketch algorithm that allows you to approximate
in the stream. Here’s a simple sketch algorithm that allows you to approximate  Let
Let 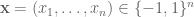 be a random vector where the
be a random vector where the 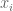 are 4-wise independent and unbiased. Consider
are 4-wise independent and unbiased. Consider 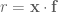 and note that
and note that  can be computed incrementally as the stream arrives (given that
can be computed incrementally as the stream arrives (given that 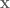 is implicitly stored by the algorithm.)
is implicitly stored by the algorithm.)
By the weaker assumption of 2-wise independence, we observe that ![E[x_i x_j]=0](https://s0.wp.com/latex.php?latex=E%5Bx_i+x_j%5D%3D0&bg=ffffff&fg=545454&s=0&c=20201002) if
if 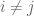 and so:
and so:
![E[r^2]=\sum_{i,j\in [n]} f_i f_j E[x_i x_j]=F_2](https://s0.wp.com/latex.php?latex=E%5Br%5E2%5D%3D%5Csum_%7Bi%2Cj%5Cin+%5Bn%5D%7D+f_i+f_j+E%5Bx_i+x_j%5D%3DF_2&bg=ffffff&fg=545454&s=0&c=20201002)
By the assumption of 4-wise independence, we also observe that ![E[x_i x_j x_k x_l]=0](https://s0.wp.com/latex.php?latex=E%5Bx_i+x_j+x_k+x_l%5D%3D0&bg=ffffff&fg=545454&s=0&c=20201002) unless
unless 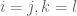 or
or  or
or 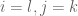 and so:
and so:
![\mbox{Var}[r^2]= \sum_{i,j,k,l\in [n]} f_i f_j f_k f_l E[x_i x_j x_k x_l]-F_2^2=4\sum_{i<j} f_i^2f_j^2\leq 2 F_2^2](https://s0.wp.com/latex.php?latex=%5Cmbox%7BVar%7D%5Br%5E2%5D%3D+%5Csum_%7Bi%2Cj%2Ck%2Cl%5Cin+%5Bn%5D%7D+f_i+f_j+f_k+f_l+E%5Bx_i+x_j+x_k+x_l%5D-F_2%5E2%3D4%5Csum_%7Bi%3Cj%7D+f_i%5E2f_j%5E2%5Cleq+2+F_2%5E2&bg=ffffff&fg=545454&s=0&c=20201002)
Hence, if we repeat the process with 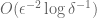 independent copies of
independent copies of  , it’s possible to show (via Chebyshev and Chernoff bounds) that by appropriately averaging the results, we get a value that is within a factor
, it’s possible to show (via Chebyshev and Chernoff bounds) that by appropriately averaging the results, we get a value that is within a factor 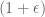 of
of 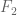 with probability at least
with probability at least 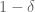 . Note that it was lucky that we didn’t need full coordinate independence because that would have required
. Note that it was lucky that we didn’t need full coordinate independence because that would have required  bits just to remember . It can be shown that remembering
bits just to remember . It can be shown that remembering  bits is sufficient if we only need 4-wise independence.
bits is sufficient if we only need 4-wise independence.
BONUS! The recent work… Having at least 4-wise independence seemed pretty important to getting a good bound on the variance of 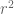 . However, it was observed in [Indyk, McGregor] that the following also worked. First pick
. However, it was observed in [Indyk, McGregor] that the following also worked. First pick 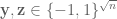 where
where  are independent and the coordinates of each are 4-wise independent. Then let the coordinate values of be
are independent and the coordinates of each are 4-wise independent. Then let the coordinate values of be 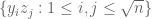 . It’s no longer the case that the coordinates are 4-wise independent but it’s still possible to show that
. It’s no longer the case that the coordinates are 4-wise independent but it’s still possible to show that ![\mbox{Var}[r^2]=O(F_2^2)](https://s0.wp.com/latex.php?latex=%5Cmbox%7BVar%7D%5Br%5E2%5D%3DO%28F_2%5E2%29&bg=ffffff&fg=545454&s=0&c=20201002) and this is good enough for our purposes.
and this is good enough for our purposes.
In follow up work by [Braverman, Ostrovsky] and [Chung, Liu, Mitzenmacher], it was shown that you can push this idea further and define based on  random vectors of length
random vectors of length  . The culmination of this work shows that the variance increases to at most
. The culmination of this work shows that the variance increases to at most 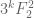 and the resultant algorithm uses
and the resultant algorithm uses 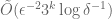 space.
space.
At this point, you’d be excused for asking why we all cared about such a construction. The reason is that it’s an important technical step in solving the following problem: given a stream of tuples from ![[n]^k](https://s0.wp.com/latex.php?latex=%5Bn%5D%5Ek&bg=ffffff&fg=545454&s=0&c=20201002) , can we determine if the coordinates are independent? In particular, how “far” is the joint distribution from the product distribution defined by considering the frequency of each value in each coordinate separately. When “far” is measured in terms of the Euclidean distance, a neat solution is based on the above analysis. Check out the papers for the details.
, can we determine if the coordinates are independent? In particular, how “far” is the joint distribution from the product distribution defined by considering the frequency of each value in each coordinate separately. When “far” is measured in terms of the Euclidean distance, a neat solution is based on the above analysis. Check out the papers for the details.
If you want to measure independence in terms of the variational distance, check out [Braverman, Ostrovsky]. In the case 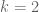 , measuring independence in terms of the KL-divergence gives the mutual information. For this, see [Indyk, McGregor] again.
, measuring independence in terms of the KL-divergence gives the mutual information. For this, see [Indyk, McGregor] again.


6 comments
Comments feed for this article
September 28, 2009 at 9:48 am
anon
The AMS sketch can be interpreted as Johnson-Lindenstrauss, or a +1/-1 version of it. Do these weaker independence version of AMS lead to any improvement in the JL space? How do your “distance-from-independent” results translate to that space?
September 28, 2009 at 11:28 am
polylogblog
AMS and JL are indeed related but note that AMS doesn’t immediately give JL because of some details that I glossed over when I referred to “appropriately averaging.” This involves taking both medians and means. Had it just been means then the correspondence would have been stronger…
AMS will map m points p1, …, pm in R^n to q1, …, qm in R^k where k=O(eps^{-2} log m) such that qi and qj can be used to estimate l2(pi-pj) up to a (1+eps) factor. However, it’s not the case that it is sufficient to use a scaled l2(qi-qj) for the estimate.
However, take a look at
Click to access p93.pdf
for another result in this direction.
The relationship between “distance-from-independence” and metric embeddings is an interesting question that may be good to think about. I’d initially thought something “deeper” was going on when Piotr and I could get a 1+eps approx for l2 but only a O(log n) approx for l1. But now Braverman and Ostrovsky have a 1+eps approx for l1 so that aspect is less mysterious than I thought.
September 28, 2009 at 2:10 pm
kay
I indeed had Dimitiri’s paper in mind, but had forgotten that AMS do the median of means. So am I correct in concluding that l2(qi-qj) would work with truly random +1/-1 bits, and AMS magically allows us to use much limited randomness, if we are willing to do something slightly more complicated. And your work allows us to further reduce the randomness needed. Are there any known results on how far one can hope to go, i.e. lower bounds on the amount of randomness needed?
September 30, 2009 at 3:33 pm
Andrew
Yes, that’s a fair summary although I’d be wary about thinking about the recent work as further reducing the randomness since the number of truly random bits is still going to be \Omega(log n) for each x. In fact, since the number of x’s that we need to use grows with the variance, we would probably end up using more random bits.
As far as a limit on how far randomness can be reduced, AMS show that any deterministic algorithm that approximates F2 within a factor 1.1 requires \Omega(n) bits of space. From this we can deduce that any randomized algorithm using o(n/s) space requires log s random bits.
December 7, 2009 at 3:58 am
STACS accepts… « the polylogblog
[…] I’ll be posting about [Epstein, Levin, Mestre and Segev] soonish. The [Ostrovsky, Braverman] paper is the same one I mentioned previously. […]
February 9, 2010 at 10:46 pm
STOC accepts… « the polylogblog
[…] Lost Letter had a great post about [Magniez, Mathieu, Nayak] and I previously mentioned the main problem from [Braverman, Ostrovsky]. I have a soft spot for both because they resolve some […]